| PCIE总线理解笔记 | 您所在的位置:网站首页 › pcie 地址映射 › PCIE总线理解笔记 |
PCIE总线理解笔记
|
基本介绍
网上有和多好的网站可以看比如下面这个,我写笔记是从嵌入式底层开始的学习记录不完整和成体系。 一篇很好的文章可以看看 PCI的EP和RC分别对应从模式和主模式,普通的PCI RC主模式可以用于连接PCI-E以太网芯片或PCI-E的硬盘等外设。RC模式使用外设一般都有LINUX 驱动程序,安装好驱动基本都能正常使用。但是对于SOC芯片本身能做EP有能做RC 两者如何互相通信可能就需要对PCIE的使用和基本原理有所了解才能较好的使用。TLP、BAR和PCIE Memory 内存访问和IO访问差别等一些定义进行了简单说明。 几个概念说明
PCIe存储器、配置、IO读写请求和原子操作、消息报文 TLP和DLLP发送的概况
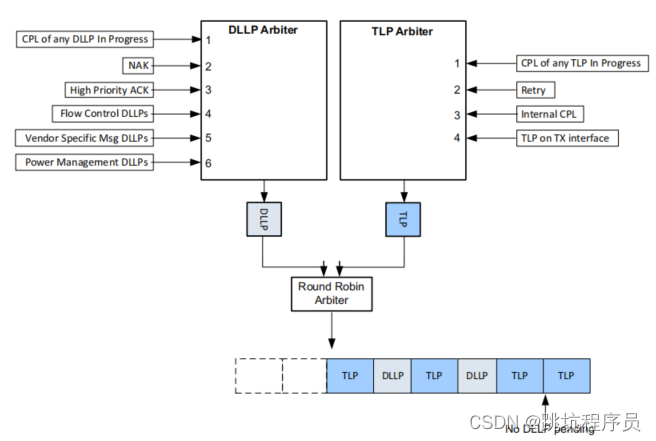
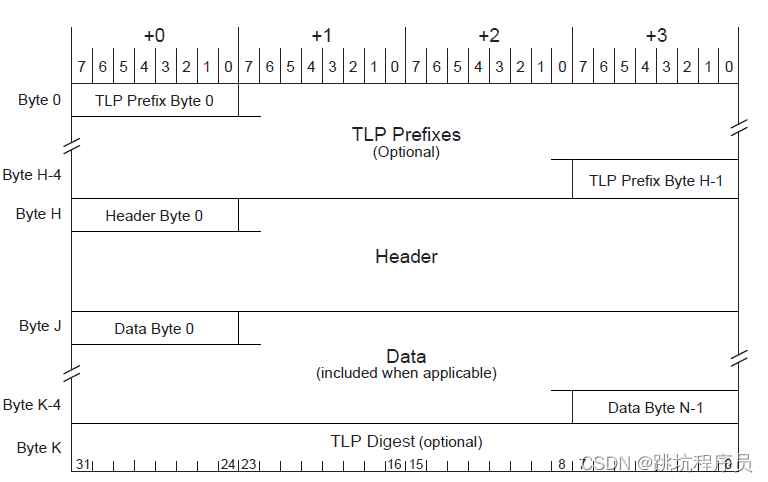
TLP(Transaction Layer Packet)据包的描述被定义为事务层数据包 (TLP),它与 PCIe 的最上层有关。数据链路层负责确保每个 TLP 正确到达其目的地。它用自己的报头和链路 CRC 包装 TLP,从而确保 TLP 的完整性。确认重传机制确保在途中不会丢失任何 TLP。流量控制机制确保仅当链路伙伴准备好接收数据包时才发送数据包。 用于访问四个地址空间的 TLP 当事务在 PCI Express 请求者和完成者之间执行时,使用了四个独立的地址空间:内存、IO、配置和消息。 地址空间传输类型描述Memory读写将数据传入或传出系统内存映射中的某个位置(内存操作使用)IO读写将数据传入或传出系统 IO 空间的某个位置(寄存器操作使用)Configuration读写将数据传入或传出 PCI 兼容设备的配置空间中的某个位置。Message发送信息一般带内消息传递和事件报告(不消耗内存或 IO 地址资源) DLLP数据链路层数据包 (DLLP) Ack DLLP 用于确认成功接收到的 TLP。 Nack DLLP 用于指示到达的 TLP 已损坏,并且应进行重传。请注意,还有一个超时机制,以防看起来像 TLP 的任何东西都没有到达。 流控制 DLLP:InitFC1、InitFC2 和 UpdateFC,用于宣布信用,如下所述。 电源管理 DLLP。 PCIE 事务 数据包结构详细说明链接 有了IP核之后,实际上我们最关心的就是事务层包的数据格式。 事务层数据包(TLP)主要由:一个或多个可选的前缀(TLP Prefixes)、一个帧头(TLP Header)、一个数据有效负载(Data Payload)和一个可选的摘要(TLP Dignest)组成,下面简单介绍一下各部分。
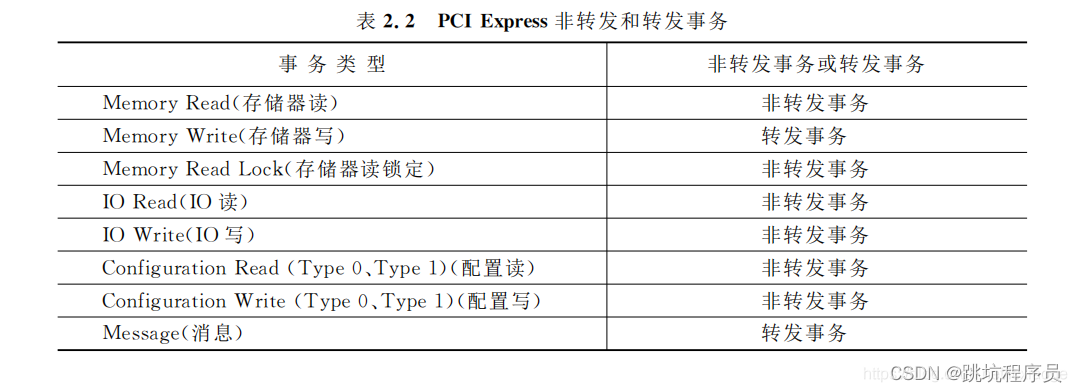
前缀(TLP Prefixes) 有PCIe V2.1总规范引入,主要起扩展帧头的作用。如果用不到,可以省去该字段。 帧头(TLP Header) TLP Header是TLP中最重要的标志,不同的TLP其头的定义并不相同。TLP 头标长3 或者4 个DW(DW = double word——双字,32位),格式和内容随事物类型变化; 数据有效负载(Data Payload) 即主设备要传输的数据。数据的长度最小为0,最大为1024DW,视具体情况而定。该字段也是一个可选项,因为有些TLP并不需要传递数据,如存储器读请求、配置和I/O写完成TLP也不需要。 摘要(TLP Dignest) 摘要是一个可选项,长度为1DW。一个TLP是否需要Dignes是由Header中TD字段决定。如果接受设备支持ECRC校验的功能的话,则该字段用来防止TLP中的数据校验码ECRC。 事务的Non-posted和posted有关事务非转发或转发的描述链接 Non-posted(非转发)事务和-posted(转发)事务都是PCIE TLP(事务层包)类型。Non-posted TLP有返回TLP,而posted事务没有返回。记忆技巧:非转发事务非要返回。本文中说的事务指的是PCIE事务层TLP。 1、两者有什么区别? Non-posted事务分为两个部分,首先是发送端向接收端发送TLP请求,接收端接收到请求完成后向发送端发送完成(Completion)TLP。包含:发送–接收–反馈三个过程。Non-posted事务必须等待接收到完成TLP,PCIE总线才能结束当前的TLP。 Posted TLP不需要完成TLP返回,此种方式中,TLP还没达到最终目的地之前,PCIE总线就可以结束当前的事务。 PCIE RC主机可以通过配置空间对PCIE EP 进行信息读取和控制。 IO区对于PCIE来说有固定格式标准。 在Linux下使用lspci -xxx 可以查看内容的二进制和lspci -vvv 查看内容对应的信息说明。 本段配置空间详细说明链接 空间访问Memory & IO 地址空间 早期的PC中,所有的IO设备(除了存储设备之外的设备)的内部存储或者寄存器都只能通过IO地址空间进行访问。但是这种方式局限性很大,而且效率低,于是乎,软件开发者和硬件厂商都不能忍了……然后一种新的东西就出来了——MMIO。 MMIO,即Memory Mapped IO,也就是说把这些IO设备中的内部存储和寄存器都映射到统一的存储地址空间(Memory Address Space)中。 P-MMIO,即可预取的MMIO(Prefetchable MMIO); NP-MMIO,即不可预取的MMIO(Non-Prefetchable MMIO)。其中P-MMIO读取数据并不会改变数据的值。 I/O space mapped cleanly to CPU semantics 1.32-bits of address space 2 .Actually much larger than CPUs of the time 3 .Non-burstable – Most PCI implementations didn’t support – PCI-X codified – Carries forward to PCI Expres 我认为主要是Non-burstable,Burstable的差异是内存访问和IO访问的最大的差异在32位处理器上。Burstable突发操作主要是正对内存的,一次突发可以同时操作多个连续地址的内存,突发可以让读写速度加快减少SOC内部总线占用,比如CPU的CACHE预取和刷新内存数据和指令时会除非突发访问,在SOC的设备寄存器操作一般是不能使用突发操作。从设置看来IO 空间可以和Memory内存空间重叠是可以的,只是不同的模式访问方式由一定差异,要注意对应使用合适的访问方式。 Message主要有九个类型: INTx Interrupt Signaling中断消息Power Management电源管理消息Error Signaling错误消息Locked Transaction Support锁定传输支持Slot Power Limit Support设置插槽功率限制消息Vendor‐Defined Messages厂家定义消息Ignored Messages (related to Hot‐Plug support in spec revision 1.1)忽略的消息Latency Tolerance Reporting (LTR)可选特性,延迟容忍信息消息Optimized Buffer Flush and Fill (OBFF)OBFF 给 PCIe 设备提供了一种获取系统电源状态的机制。利用 OBFF,PCIe 设备就可以选择与系统进行数据交互的最优时间。 PCIE 配置
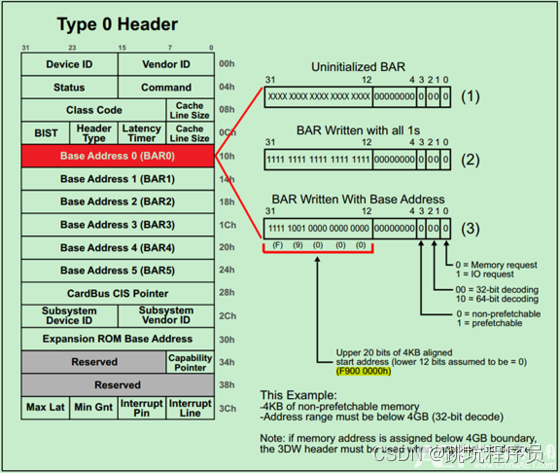
设置两种不同类型的说明链接 PCI总线定义了两类配置请求,一个是Type 00h配置请求,另一个是Type 01h配置请求。PCI总线使用这些配置请求访问PCI总线树上的设备配置空间,包括PCI桥和PCI Agent设备的配置空间。 其中Type0 Header最多有6个BAR,而Type1 Header最多有两个BAR。 这就意味着,对于Endpoint来说,最多可以拥有6个不同的地址空间。但是实际应用中基本上不会用到6个,通常1~3个BAR比较常见。主要注意的是,如果某个设备的BAR没有被全部使用,则对应的BAR应被硬件全被设置为0,并且告知软件这些BAR是不可以操作的。而这些不可操作的低比特决定了当前BAR支持的操作类型和可申请的地址空间的大小。 一旦BAR的值确定了(Have been programmed),其指定范围内的当前设备中的内部寄存器(或内部存储空间)就可以被访问了。当该设备确认某一个请求(Request)中的地址在自己的BAR的范围内,便会接受这请求。 BAR和ATUBAR和ATU的关系 BAR和ATU关系加LINUX的ATU驱动分析 我理解BAR 和ATU的关系: tlp中的地址就是atu转换后的地址,bar就是接受对应的转换后的地址。我先理解为ATU是发起端地址转换,bar是接收端的对应地址访问设置。我使用的IP ATU有个BAR match模式,使用BAR来控制ATU的输入范围。 BAR的值确定了(Have been programmed),其指定范围内的当前设备中的内部寄存器(或内部存储空间)就可以被访问了。当该设备确认某一个请求(Request)中的地址在自己的BAR的范围内,便会接受这请求。 BAR地址不一定等于FPGA或CPU内部地址,他们是可以进行设置的ATU 的inband输入设置对应进行范围对应。 BARBAR是基地址寄存器在配置空间(Configuration Space),在PCIE的初始化步骤中就需要对BAR的范围进行配置。在SPARC处理器的设计中也有BAR的设置,类似与把SOC的地址空间分断。通过BAR的配置可以设置地址空间断有不同的属性,比如可否访问、CACHE的命中等,也直接影响到前面提到的Non-burstable不能突发访问,Burstable突发的差异。 BAR的设置的最终效果下面这幅图能够很好的说明BAR的作用,实际上就是就是空间进行映射,最后达到访问从机的指定区域地址就像访问SOC处理器的内部地址空间一样。不需要软件做特殊的控制,从机的资源像是自身内部空间。 以个人使用的一个PCIE控制器进行介绍该控制器为DWC_pice控制器 控制器为每个实现的功能提供三对 32 位 BAR。 每对(BAR 0 和 1, BAR 2 和 3、BAR 4 和 5) 可以配置如下: ■ 一个64 位BAR:例如,BAR 0 和1 组合形成一个64 位BAR。 ■ 两个32 位BAR:例如,BAR 0 和1 是两个独立的32 位BAR。 ■ 一个 32 位 BAR:例如,BAR0 是一个 32 位 BAR,而 BAR1 被禁用或从
该控制器有6对BAR的设置寄存器,可以通过两个相邻的寄存器配置成支持64位空间,也可以每个单独的配置成32位的空间配置。上图就是一个简单说明,BAR的寄存器设置如下: BIT0位配置IO/MEM选择:设置0为内存空间,设置1为IO空间; BIT2:1位配置BAR类型:设置0位32BITBAR; BIT3位配BAR设置为Memory空间的预取使能:把I/O寄存器实现成内存区间的PCI设备可以通过设定其配置空间寄存器的"内存为可预取"位(bit)来标明某地址区间是否可预取。如果内存区间被标记为可预取,那么CPU便会缓存其内容,访问时会进行各种优化方法;相反,访问不可预取内存时就不能进行优化,因为每次访问都伴随副作用,就和I/O端口一样。将其控制寄存器映射到内存地址范围的外设会把该范围置为不可预取,不过诸如PCI板卡上的显示内存(video memory)之类都是可预取的。(最简单的理解为,预先读取了你当前程序访问的地址的后几个值,当你程序访问后面紧接的地址值时,PCIE总线不再发起真正的读操作,你获取的实际是上一次访问获取的值。在有的时候后面的值在第一次访问后变了,你却不能获取最新状态。) 对于Memory BAR,BAR 位 [11:0] 总是被屏蔽。 控制器要求每个内存 BAR 在至少 4 KB。 对于 I/O BAR,BAR 位 [7:0] 总是被屏蔽。 控制器要求每个 I/O BAR 至少声明 256B。 一个简单的BAR操作例子BAR操作步骤原文 对应DW的操作看《DW PCIE 的Register Module, LBC, and DBI章节学习笔记》和连接的有点差异。 32-bit Memory Address Space Request: 如下图所示,请求一个4KB的NP-MMIO一般需要以下三个步骤:
Step1:如图中(1)所示,未初始化的BAR的低比特(114)都是0,高比特(3112)都是不确定的值。所谓初始化,就是系统(软件)向整个BAR都写1,来确定BAR的可操作的最低位是哪一位。当前可操作的最低位为12,因此当前BAR可申请的(最小)地址空间大小为4KB(212)。如果可操作的最低位为20,则该BAR可申请的(最小)地址空间大小为1MB(220)。 Step2:完成初始化(写1操作)之后,软件便开始读取BAR的值,来确定每一个BAR对应的地址空间大小和类型。其中操作的类型一般由最低四位所决定,具体如上图右侧部分所示。 Step3:最后一步是,软件向BAR的高比特写入地址空间的起始地址(Start Address)。如图中所示,为0xF9000000。 EP模式中断
PCIE 使用MSI MSI: Message Signaled Interrupt MSI-X: Message Signaled Interrupt eXtended MSI和MSI-X的比较 MSI机制只允许每个PCI Function最多拥有32个中断向量,这对某些应用来说完全不够 MSI机制下每个PCI Function的所有中断向量都共用1个Message Address,无法将其分配到不同CPU以实现中断服务在CPU间均衡分配 MSI机制下每个PCI Function的所有中断向量都是连续的,在某些平台连续的中断向量意味着同样的中断优先级,无法满足区分中断优先级的需求 EP模式测试简单说明一些细节的介绍可以去看看一个测试案例:http://software-dl.ti.com/jacinto7/esd/processor-sdk-linux-jacinto7/06_02_00_07/exports/docs/linux/Foundational_Components/Kernel/Kernel_Drivers/PCIe/PCIe_End_Point.html 查看使用和说明。 EP的配置Linux 配置使能PIC 和对应IP的EP模式,在板的DTS上设置EP信息并使能。 CONFIG_PCI_ENDPOINT=y CONFIG_PCI_ENDPOINT_CONFIGFS=y CONFIG_PCI_EPF_TEST=y在系统中查询到端点设设备 root:~# ls /sys/class/pci_epc/ d000000.pcie-ep要在系统中查找端点功能驱动程序列表: root:~# ls /sys/bus/pci-epf/drivers pci_epf_test pci_epf_ntb RC的配置Linux 配置使能PIC 和对应IP的RC模式,在板的DTS上设RC信息并使能。 CONFIG_PCI=y CONFIG_PCI_ENDPOINT_TEST=y查询PCIE从设置 root:~#lspci output 0000:00:00.0 PCI bridge: Texas Instruments Device b00d 0000:01:00.0 Unassigned class [ff00]: Texas Instruments Device b00d 0000:01:00.1 Unassigned class [ff00]: Texas Instruments Device b00d 0000:01:00.2 Unassigned class [ff00]: Texas Instruments Device b00d 0000:01:00.3 Unassigned class [ff00]: Texas Instruments Device b00d 0000:01:00.4 Unassigned class [ff00]: Texas Instruments Device b00d 0000:01:00.5 Unassigned class [ff00]: Texas Instruments Device b00d 0001:00:00.0 PCI bridge: Texas Instruments Device b00d 0002:00:00.0 PCI bridge: Texas Instruments Device b00d一个比较好的网站 https://www.cnblogs.com/yi-mu-xi/p/10932432.html ATU控制器使用 ATU 实现本地地址转换方案,该方案替换当前 TLP 请求标头中的 TLP 地址和 TLP 标头字段。这是和总线对接的一个模块,除了地址转换之外,还根据配置产生tlp。一般是这样的,系统会为PCIe设备预留256MB空间,访问这256MB空间的时候就会触发产生一个mem request tlp,然后ATU根据配置(如果配置了cfg type)将其转换成cfg request,其中的target地址就写入了tlp中。然后PCIe网络就将这个tlp路由到对应地址的设备功能上了。举例如下: 系统ram空间地址基址为0x40000000,ATU配置source address为0x40000000,target address为0x00000000,ATU type = cfg 0,size=0x10000000(256MB),那么CPU读0x40000000地址的时候触发了一个mem read request,经过ATU之后产生了一个cfg type 0 rd的request;同样的,如果往0x40000000写一笔数据,就会触发mem write request,处理过程也是类似的。如果访问0x40100000,转换后的target地址就成了0x100000。 Generally speaking, if your card has SoC, the FW on the SoC will configure the iATU mapping with BAR match mode. And don’t let host side driver to configure it.> 是不是如果配置的和BAR相关就不用考虑配置该部分? PCIE 正常信息查询使用lspci -vvv 命令检查 root@arm:~/ngbe# lspci -vvv 00:00.0 PCI bridge: Synopsys, Inc. Device abcd (rev 01) (prog-if 00 [Normal decode]) Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr+ Stepping- SERR+ FastB2B- DisINTx- Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- |

 在很多地方都没有找到PICE内存操作和IO操作的差异,有的人提到X86的IO空间但是其实和那个没有关系,ARM和X86的IO空间的问题。从最后找到资料来看其实主要差异是如下说明: Memory space mapped cleanly to CPU semantics 1.32-bits of address space initially 2. 64-bits introduced via Dual-Address Cycles (DAC) – Extra clock of address time on PCI/PCI-X – 4 DWORD header in PCI Express 3 Burstable
在很多地方都没有找到PICE内存操作和IO操作的差异,有的人提到X86的IO空间但是其实和那个没有关系,ARM和X86的IO空间的问题。从最后找到资料来看其实主要差异是如下说明: Memory space mapped cleanly to CPU semantics 1.32-bits of address space initially 2. 64-bits introduced via Dual-Address Cycles (DAC) – Extra clock of address time on PCI/PCI-X – 4 DWORD header in PCI Express 3 Burstable 其中10H-24H 可以根据设置体现两种格式。 Type0是Endpoint用,Type1主要是RC或PCIE桥使用。
其中10H-24H 可以根据设置体现两种格式。 Type0是Endpoint用,Type1主要是RC或PCIE桥使用。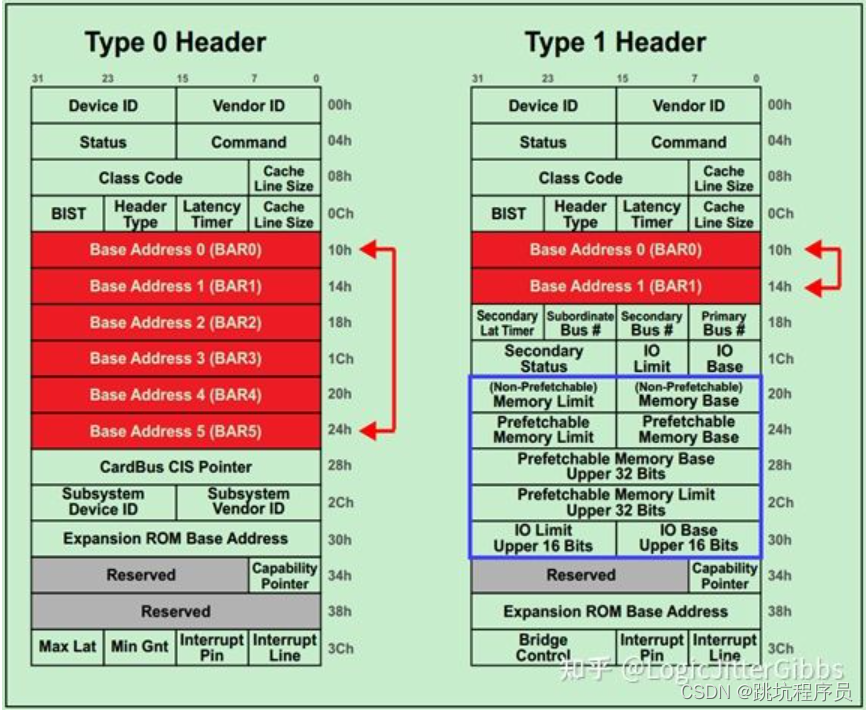


 PCIe完全继承了PCI的所有的中断特性(包括INTx,MSI/MSIx)。但是与PCI不同的是,PCIe使用串行总线尽量减少pin的使用,所以对于INTX类型的中断,它没有使用sideband pin(单独使用中断管脚)的方式而是使用Message传递中断(前面消息中有介绍)。另外对于PCI, MSI/MSIX是可选的但是PCIe设备必须支持MSI/MSIx的中断请求机制,可以不支持INTx中断消息(我使用的SOC就不支持INTx中断)。
PCIe完全继承了PCI的所有的中断特性(包括INTx,MSI/MSIx)。但是与PCI不同的是,PCIe使用串行总线尽量减少pin的使用,所以对于INTX类型的中断,它没有使用sideband pin(单独使用中断管脚)的方式而是使用Message传递中断(前面消息中有介绍)。另外对于PCI, MSI/MSIX是可选的但是PCIe设备必须支持MSI/MSIx的中断请求机制,可以不支持INTx中断消息(我使用的SOC就不支持INTx中断)。【本文地址】